
Relational Future Captioning Model for Explaining Likely Collisions in Daily Tasks

Domestic service robots that support daily tasks are a promising solution for elderly or disabled people. It is crucial for domestic service robots to explain the collision risk before they perform actions.
In this paper, our aim is to generate a caption about a future event. We propose the Relational Future Captioning Model (RFCM), a crossmodal language generation model for the future captioning task.
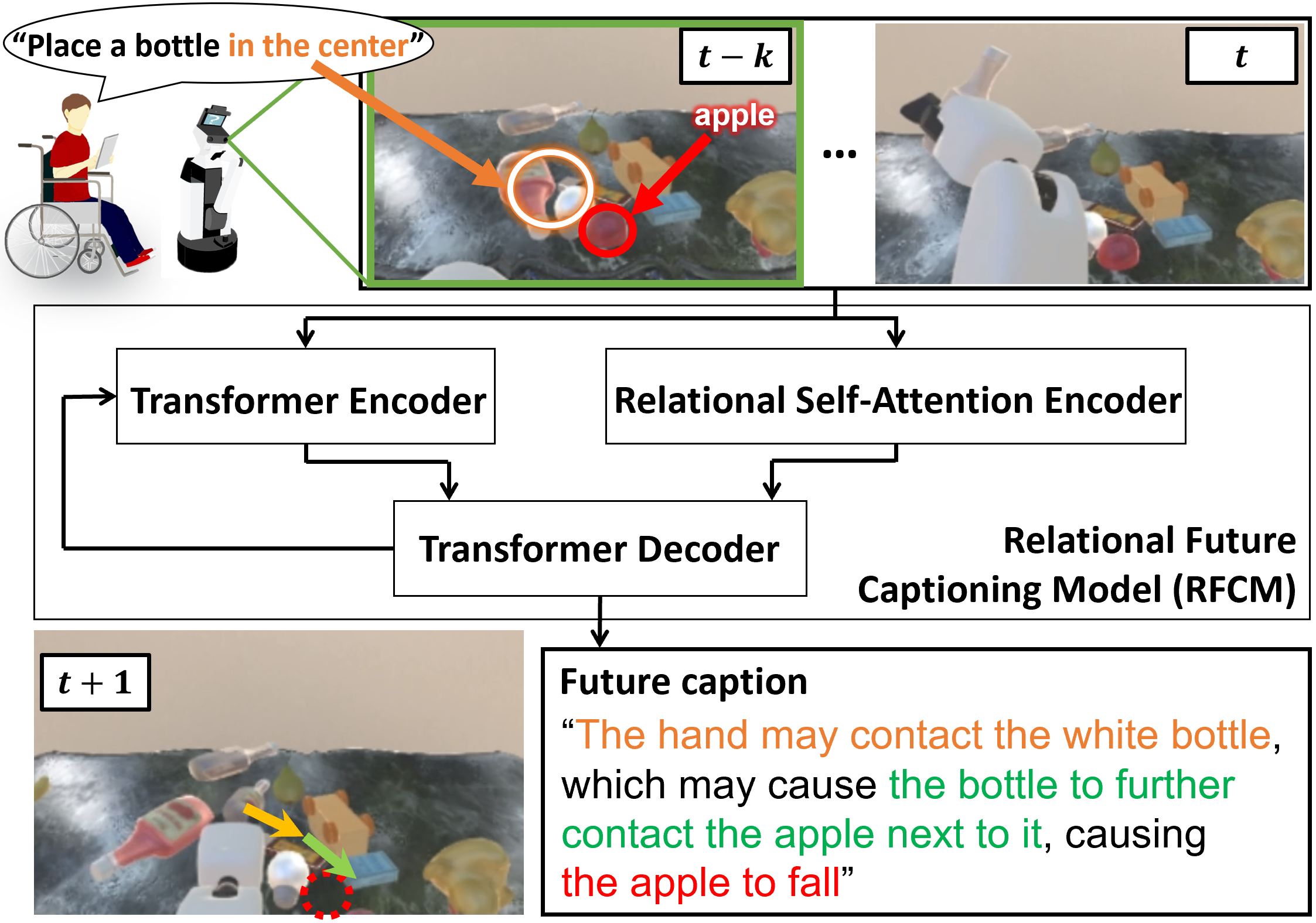
The RFCM has the Relational Self-Attention Encoder to extract the relationships between events more effectively than the conventional self attention in transformers. We conducted comparison experiments, and the results show the RFCM outperforms a baseline method on two datasets.
