
Case Relation Transformer: A Crossmodal Language Generation Model for Fetching Instructions
There have been many studies in robotics to improve the communication skills of domestic service robots. Most studies, however, have not fully benefited from recent advances in deep neural networks because the training datasets are not large enough. In this paper, our aim is crossmodal language generation.
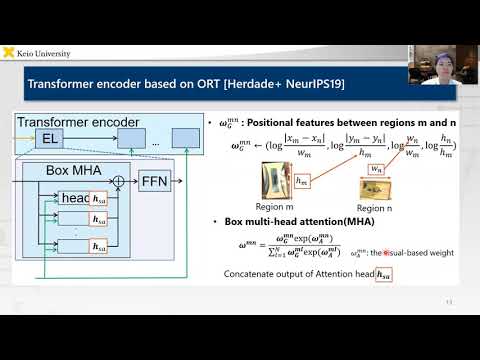
We propose the Case Relation Transformer (CRT), which generates a fetching instruction sentence from an image, such as “Move the blue flip-flop to the lower left box.” Unlike existing methods, the CRT uses the Transformer to integrate the visual features and geometry features of objects in the image. The CRT can handle the objects because of the Case Relation Block.
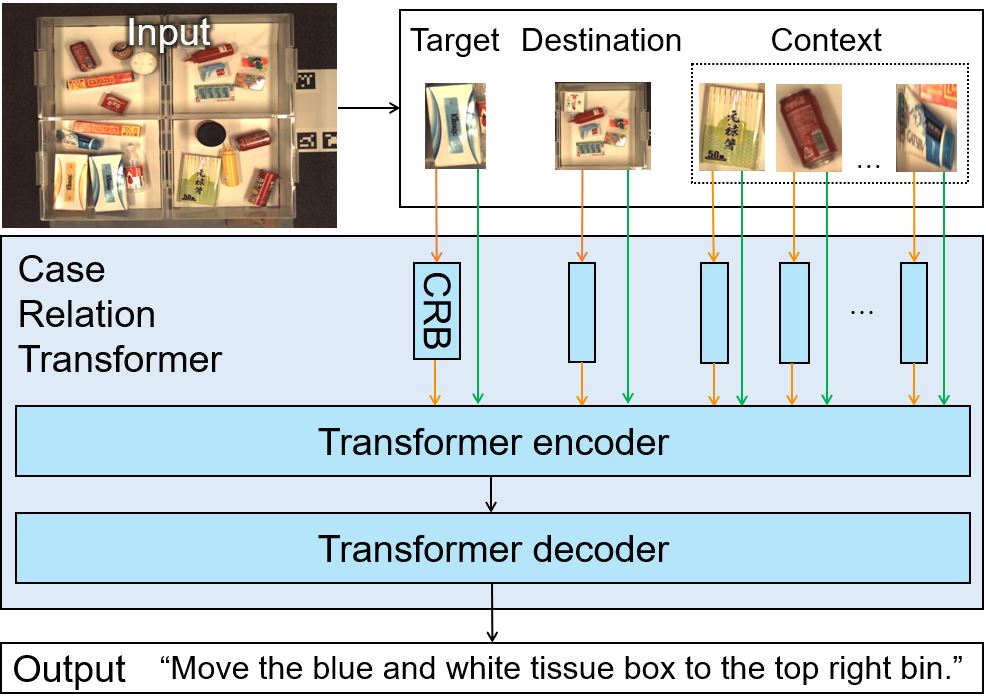
We conducted comparison experiments and a human evaluation. The experimental results show the CRT outperforms baseline methods.

